
Test Automation Strategy
Test automation is a cornerstone of teams that deliver quality at speed, but naive approaches are costly. Getting test automation right requires a deep understanding of the tools in your testing toolbox.
14 minute read
Continuous automated testing enables teams to create value at a high rate of speed while maintaining quality and stability. However, despite the evidence, there’s plenty of skepticism remaining in the industry about the value of test automation. In my experience that skepticism comes from two places.
The first is that people correctly point out that when you write automated tests you have to write and maintain more code than you would otherwise write, but incorrectly deduce that testing, therefore, reduces speed. If I have to write a feature that is going to take 100 lines of production code and another 100 lines of test code then I’ve effectively doubled the amount of work I have to do, and therefore testing slows me down by an unacceptable amount, right? This conclusion is flawed for a ton of reasons, but the most important is that the argument only works if you narrow your focus down to a single programming task. Sometimes a single coding task WILL take longer because of all of the test automation needed to support that work safely. But, with good test automation in place, the team will create more value week over week because they are working with tight feedback loops and are dealing with vastly less unplanned work.
The second reason that people are skeptical of automated testing is that they’ve tried to implement it in the past, or they’ve worked on teams where it was implemented, and the results were middling or horrible. That’s because test automation, implemented naively, adds little or no value. It’s important to get it right in order realize the benefits.
One of the important things to understand when trying to get test automation right is that there is a need for a bit of strategy. There are lots of different kinds of automated tests that serve lots of purposes. You need to choose the right kinds of tests in the right distribution, and then implement them correctly, in order to build a mistake-proof software system.
Classifying Automated Tests
We can classify tests along 3 primary criteria: perspective, purpose and size. Perspective describes the lens through which a test should be understood. Purpose is self-explanatory: it describes why a test exists. And size is an understanding of how much of a system is exercised when a test is run.
Any automated test strategy is composed of tests, large and small, that fill a certain purpose for a certain perspective. It’s important to know how much of what kind of test is needed in order to realize the benefit of those tests without incurring more cost than what is warranted.
Size
Size can be understood as the amount of code that has to run in order to execute a single test. The largest tests touch the database, the backend and the user interface. Small tests will touch just small pieces of the backend or the frontend in isolation.
The reason size matters is that smaller tests are cheaper to maintain and faster to run. An entire suite of hundreds of small tests can be run in seconds on dev machines. A test suite like this delivers instantaneous feedback to the dev team while they’re working and is the most powerful feedback loop we can create with test automation.
A suite of large tests might just contain 100 tests and take an hour or more to run. The feedback from these tests is far from instantaneous, but these tests are able to cover entire use cases and make sure that all of our small bits of code are connected together in a way that creates value for our customers.
The Test Pyramid
The test pyramid is a visualization used to communicate how many of what size of tests you should have. It shows that you should have many more small unit tests than large end to end tests. It is effective, but for many people this diagram is all they know about automated testing and suddenly we only have three kinds of tests: e2e, integration and unit. Where does capacity, security or deployment testing fit into all of this?
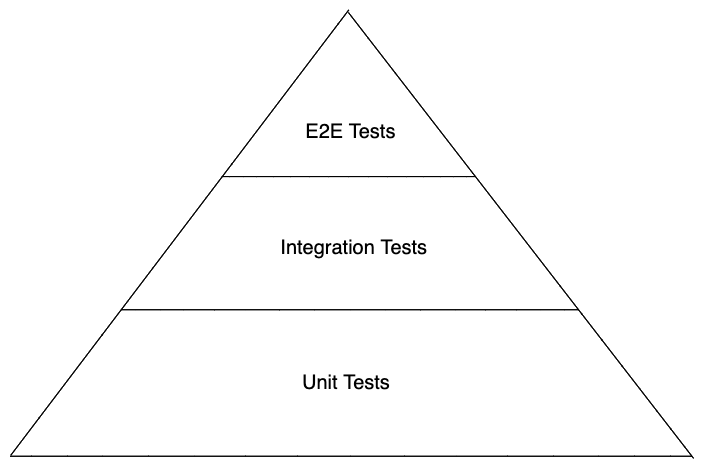
The test pyramid is good, but the important take away is simply this: most of the time you should have many more small fast tests than large slow tests.
Just to complicate things Kent C. Dodds has introduced his testing trophy. I won’t go into too much detail on that here. I think it’s right, but only on frontend SPAs and a certain kind of backend system.
Perspective and Purpose
To understand perspective and purpose we turn to the testing quadrant:

A test’s perspective is either technology-facing or business-facing. Technology-facing tests are best understood from the programmer’s perspective. They’re technical in focus and will be difficult to understand unless you have some technical background. Business-facing tests, on the other hand, serve to validate that the system is fit for purpose from the perspective of business interests and users.
A test’s purpose is to either support the team or critique the product. Tests that support the team are used by the team to make sure that we’re building the right thing and building it well. These tests are run on developer machines and built into a fast feedback pipeline and used to build quality into our products. Critiquing the product is less about preventing defects and more about improving functional and nonfunctional quality of outcomes. The key difference is really when tests are run. Supporting tests run during development and critiquing tests run after development is complete.
Types of Automated Tests
The kinds of tests I document here will make up a set of tools in our toolbox. A good test strategy requires some knowledge of all the tools you have available, and which tool to apply in what scenario.
A word of caution here: being too rigid about classifying tests as a “type” can lead you down a naive path and keep you from being creative about testing. Nevertheless, there are common names for types of tests, and it is useful to use them.
Unit Tests
Small, technology-facing tests that support the team.
Unit tests are the smallest kind of test. They focus on small pieces of code like a function or a class. They might test a couple functions or classes at a time. They are fast. A unit test suite that takes longer than 10 seconds should be considered too slow. Certainly measuring in minutes means you’re trending in the wrong direction.
I like Mike Feathers’ definition from “Working Effectively with Legacy Code”.
Unit tests run fast. If they don’t run fast they aren’t unit tests. Other kinds of tests often masquerade as unit tests. A test is not a unit test if:
- It talks to a database
- It communicates across a network
- It touches the files system.
- You have to do special things to your environment (such as editing configuration files) to run it.
Unit tests are the first line of defense against defects, but their primary value is as a design tool. TDD with unit tests can be expected to produce superior software designs. It asks developers to think in terms of interfaces and seams, and to think critically about information hiding and abstraction.
Integration Tests
Medium, technology-facing tests that support the team
The word “integration” basically has no meaning anymore, but this term is commonly used so we must deal with it. In Continuous Delivery they completely avoid the term and use “Component Tests” to describe this kind of testing instead. The goal of testing at this level of abstraction is to make sure that our larger components are functioning correctly together. Generally we DO run a database for integration testing.
The idea behind integration tests is that they’re still fast. It’ll take a couple of minutes for a whole integration suite, so it’s not unreasonable for a developer to run on their machine while they’re working. These tests verify important things like that my code integrates with my framework correctly, or that I’m creating database records correctly. These are things that are important to have fast feedback about, but impossible to have really fast feedback about, so we separate these things out and run them as a separate suite.
End to End Tests
Large tests that run the whole system
End to end (e2e) tests are large tests that run against the user interface with a real backend and database hooked up. These tests can’t be classified as having a perspective because sometimes you use e2e tests to support the team and sometimes you use them to critique the product. It’s usually more useful to talk about other kinds of tests like Acceptance Tests.
End to end tests are the slowest kind of test. A suite made up of e2e tests can take hours to run, and therefore the feedback loop that they generate is the least effective. They are also more brittle and the feedback they provide is more coarse and harder to use. This doesn’t mean that we can’t use e2e testing to do useful things, but it does mean we should use this tool sparingly. Every single test that runs end to end should be scrutinized and replaced with a smaller test if at all possible.
Acceptance Tests
Large, business-facing tests that support the team
The point of acceptance testing is to build a shared understanding of a systems current and expected behaviors. Good acceptance tests are written in a human readable language and are automated as a part of development. Incorporating good acceptance testing with processes and techniques from Behavior Driven Development is great way to realize the entire benefit of this kind of testing.
Automated acceptance tests often run end to end, but this is not required or even optimal. It is recommended to run most acceptance tests just below the “skin” of the UI. In our case this means that mostly they should run against our REST apis. I recommend a strategy that runs a small set of acceptance tests end to end, while running most (90% or more) against the application’s api.
Deployment Tests
Large, technology-facing tests that support the team
Another word for this kind of test is a “smoke test”. The idea is that you pick a small, representative sample of your regression tests (usually your acceptance tests) to validate that after an app has been deployed to a new environment that everything, including the hosting infrastructure, is configured and working correctly. These will run as a part of the deployment pipeline. When you send a new build to production you’d execute these tests before finalizing the deployment. If the tests fail then the deployment is cancelled and the team will be alerted.
Capacity Tests
Large, technology-facing tests that critique the product
Also called “load testing”. Capacity testing is about making sure that we can support the traffic and usage patterns that we expect in production. There are a lot of ways to do capacity testing, but repurposing the acceptance tests and running a lot of them in parallel for a couple of minutes is a great technique to exercise a system.
UI Tests
Small, technology-facing tests that support development
It’s tempting to lump these in with unit testing these days, but it’s distinct enough to separate. The use of react and modern javascript make our UIs much more testable than they have been in the past. Kent C. Dodds is probably the most prominent person pushing this space right now, and his blog and tools like react testing library are great resources for achieving confidence in our UI code.
These tests don’t run end to end, they isolate the UI from the rest of the technology stack. They can be used for TDD when building frontends, but the feedback isn’t quite as good as when doing non-ui TDD.
Contract Tests
Medium, technology-facing tests that support development
Contract testing is used to validate that messages and interfaces between applications conform to a shared understanding. These are useful when you have multiple services, and really shine when multiple teams are involved. Client-driven contract testing is a practice where you allow the consumers of an interface to declare “this is how I use your service” and the service provider runs those tests in order to guarantee that they won’t break their contract with the client application.
So if you work on a project where a customer team is responsible for the backend and your team is responsible for the frontend, see if you can figure out how to use Pact to write some contract tests and get our customer to work those into their CI/CD system.
Or if you’re working on a service that will be used by another team, then invite them to write contract tests to help guide development and build a shared understanding.
Regression Tests
Regression testing is a catch all term for “tests for the purpose of finding defects”. They don’t even have to be automated tests. Manual test scripts are used for regression testing all the time. In the automation world we can use all of our tests as a regression suite. The combination of unit, integration and acceptance tests becomes an extremely powerful suite that prevents regression.
One temptation will be to add tests to our test suites solely for the purpose of catching regressions. It can be problematic to do that if the tests you add don’t closely match the purpose or size of the surrounding tests. This causes the most problems in acceptance test suites, when suddenly we have a bunch of Given-When-Then language that’s laser focused on specific defects.
Many teams tried to use Given-When-Then for purposes that have nothing to do with BDD... Some wanted to just automate a bunch of regression tests to improve coverage... The result is often a mess of slow, clunky test suites that are horribly difficult to maintain... Separating “true BDD” from “fake BDD” cases helps with maintaining the core example scenarios easily
Gojko Adzic
Hybrid Tests
Tests exist on a size spectrum. If you allow yourself to be rigid and formulaic in your thinking about what an automated test is you’ll be missing out on opportunities to test better or faster.
For example, on one project, we had Repository classes that were responsible for writing and retrieving data from the database. I wanted to have some small tests that for these classes that we could use for TDD, but I didn’t want to mock the database. We felt like running a real database for these tests was important because database interaction was the whole point for these classes to exist, and we didn’t want to wait for larger api route testing to validate this functionality.
What we ended up with we just called “repository tests” and we ran the real database in order to do this testing. In practice we bundled these up with the api route tests (ie, integration tests), but they were small like unit tests. If you recall Michael Feathers’ definition from above, this means that these don’t qualify as unit tests! But they are still quite small so I don’t like calling them integration tests. What are these tests called then? The answer is “who cares?”. They’re not really either and that’s fine. We called them repository tests and moved on with our lives.
Building a Test Strategy with Automation
Cease dependence on mass inspection to achieve quality. Improve process and build quality into the product in the first place.
W. Edwards Deming
Building software is a complex undertaking, and so there is no one size fits all combination of tests that should be employed for every software product. So as you work you must understand the point of testing, the test options and the different properties for different kinds of tests. You want to build a toolbox of automated testing options.
Once you understand your toolbox, then it’s a matter of understanding the problem at hand and which tool to apply. If a software system is small, or will only be used by a handful of people, then the best testing approach is different than when a software system is huge or when failures can have catastrophic consequences.
Minimize the Cost of Change
Successful software engineering is about preserving speed and stability in order to make product experimentation easy. The best products are produced through progressive refinement, ie, small changes are made and deployed quickly, while monitoring outcomes, until some goal is achieved that maximizes some value.
Be creative about the tests you write while you’re building a feature. Use TDD with unit tests to drive your designs. Use acceptance testing to make sure you’re building the right thing.
Segment your test suites and run them at different times
As we’ve learned, not every test is created equal. Fast tests deliver more value if they can run independently of and more frequently than slow tests. Divide up your test suites by purpose, size and perspective. One test suite is for lightning fast TDD, another is to make sure the whole system is functioning right before you check in your code.
Use tags in your acceptance suite to divide up your tests. Run e2e tests independently of tests that don’t hit the UI. Make sure faster running tests run and give feedback as soon as the feedback is available.
Some Guidelines
- Testing is a cross-functional activity that involves the whole team. Use BDD to achieve this goal.
- Testing should be done continuously from the beginning of the product
- Write tests of varying size, but prefer to have many more smaller tests than bigger tests
- Automate as much as possible
- Do not tolerate flakiness in tests. False positives and false negatives destroy the value of a test suite.
- Do not tolerate failing tests. If it’s broken fix it. If it doesn’t matter delete it.
- Create high quality feedback loops to support development. Your test systems should be architected to tell you as quickly as possible if something has failed. Use continuous integration, continuous delivery, and trunk based development.
- Be creative about how to test. Don’t allow yourself to get bogged down in debates about what even is a unit anyway. Instead ask questions like “is this test fast or slow? Does it give me confidence that the system is functioning correctly? Is the confidence it gives worth its cost to maintain?”
- Remove tests that don’t add value
- Keep your feedback loops fast
Resources
Not Books
- Continuous Testing
- The Practical Test Pyramid
- Given-When-Then, tweak and try again by Gojko Adzic
- On the Diverse and Fantastical Shapes of Testing by Martin Fowler
Books
- Agile Testing by Lisa Crispin and Janet Gregory
- Continuous Delivery by David Farley and Jez Humble
- Continuous Delivery Pipelines by David Farley
- Fifty Quick Ideas To Improve Your Tests by Gojko Adzic
- Working Effectively with Legacy Code by Michael Feathers
- Refactoring by Martin Fowler
